#install.packages("sjPlot", dependencies=T) # solito porque da problmaslibrary(sjPlot)if (!require("pacman")) install.packages("pacman") # instala pacman si se requiere
Cargando paquete requerido: pacman
pacman::p_load(tidyverse, # sobretodo para dplyr haven, #importación janitor, #tablas sjlabelled, # etiquetas DescTools, # Paquete para estimaciones y pruebas infer, # tidy way broom, # Una escobita para limpiar (pero es para arreglar) estimatr, car, stargazer, ggpubr, jtools, lm.beta, robustbase, sandwich, officer,flextable,huxtable, ggstance, kableExtra, ResourceSelection, lmtest, mlogit, nnet) # Nuevos
E importamos la base e incluimos los cambios anteriores
etiqueta_sex<-c("Hombre", "Mujer")concentradohogar <- haven::read_dta("datos/concentradohogar.dta") %>%mutate(sexo_jefe=as.numeric(sexo_jefe)) %>%## para quitar el "string" sjlabelled::set_labels(sexo_jefe, labels=etiqueta_sex) %>%mutate(clase_hog=as.numeric(clase_hog)) %>%## para quitar el "string" sjlabelled::set_labels(clase_hog, labels=c("unipersonal","nuclear", "ampliado","compuesto","corresidente")) %>%mutate(educa_jefe=as.numeric(educa_jefe)) %>%set_labels(educa_jefe,labels=c("Sin instrucción", "Preescolar","Primaria incompleta","Primaria completa","Secundaria incompleta","Secundaria completa","Preparatoria incompleta","Preparatoria completa","Profesional incompleta","Profesional completa","Posgrado")) %>%mutate(ent=stringr::str_sub(folioviv, start=1, end=2 )) %>%mutate(ing_per=ing_cor/tot_integ) %>%mutate(recibe_rem=remesas>0)
7.1.1 Sub-setting y modelos clase anterior
Vamos a hacer una sub-base de nuestras posibles variables explicativas. Esto es importante porque sólo podemos comparar modelos con la misma cantidad de observaciones.
En esta práctica vamos a revisar los elementos básicos para la regresión logística. El proceso en R para todos los modelos generalizados se parece mucho. Por tanto, no será difícil que luego puedas utilizar otras funciones de enlace.
Vamos a hacer una sub-base de nuestras posibles variables explicativas. Esto es importante porque sólo podemos comparar modelos con la misma cantidad de observaciones. Intentaremos predecir la participación económica
Para interpretar mejor los coeficientes suelen exponenciarse y hablar de las veces que aumentan o disminuyen los momios con respecto a la unidad como base. Si exponenciamos a ambos lados de nuestra ecuación:
\[ \frac{p(x=1)}{p(x=0)}=e^{\beta_o+\beta_1x +\epsilon}\] Al exponenciar los coeficientes, tenemos los resultados en términos de momios.
\[ \frac{p}{1-p}=e^{\beta_o}*+*e^{\beta_1x}*e^{\epsilon}\] Por tantopodemos establecer por cuánto se multiplican los momios de probabilidad. Lo cual es una manera más sencilla para interpretar nuestros resultados
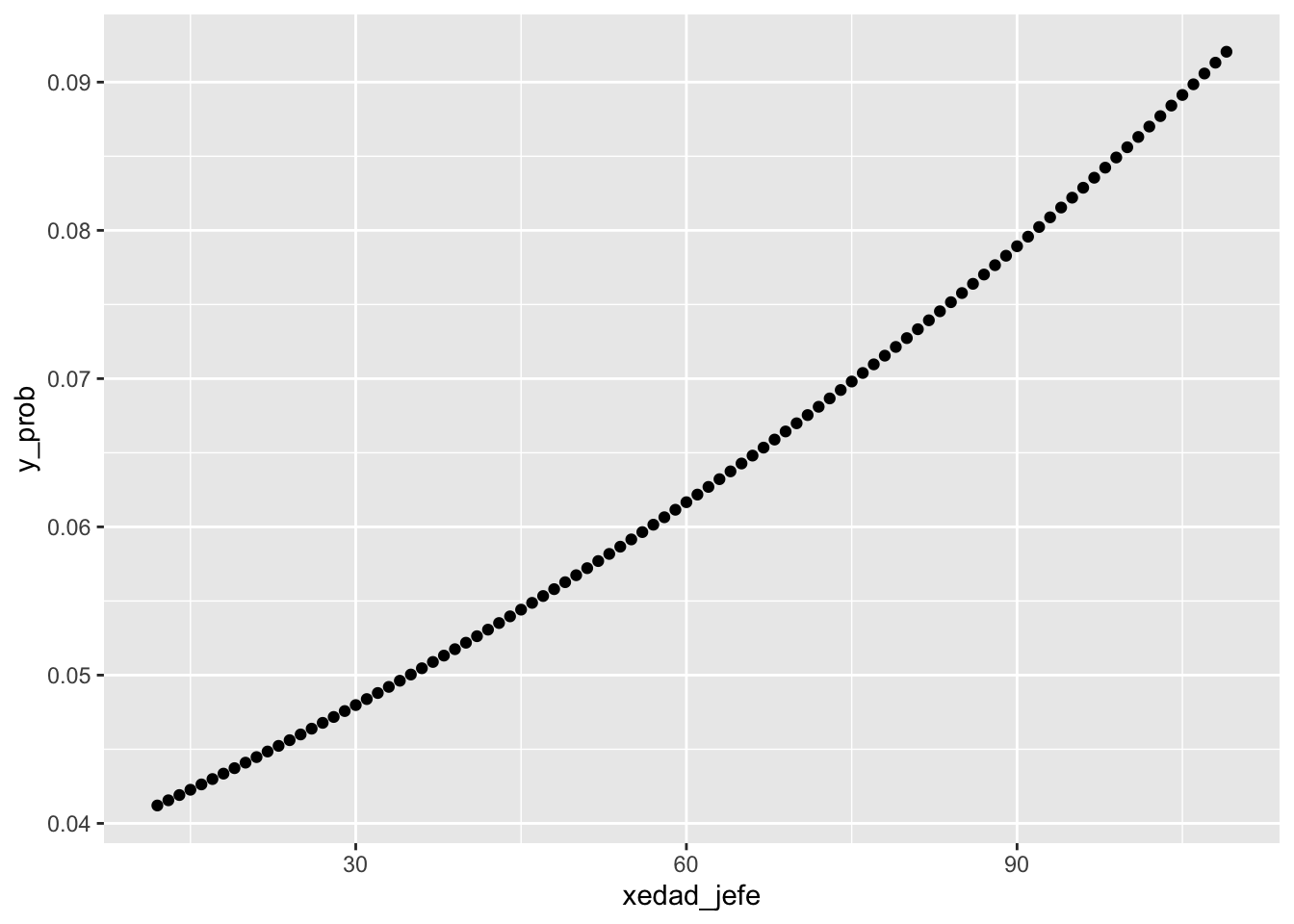
exp(coef(modelo0))
(Intercept) edad_jefe
0.03864889 1.00888670
Es muy fácil con la librería jtools, sacar los coeficientes exponenciados. La ventaja es que nos dan también los intervalos:
summ(modelo0, exp=T )
Observations
90093
Dependent variable
recibe_rem
Type
Generalized linear model
Family
binomial
Link
logit
𝛘²(1)
98.97
p
0.00
Pseudo-R² (Cragg-Uhler)
0.00
Pseudo-R² (McFadden)
0.00
AIC
39706.33
BIC
39725.15
exp(Est.)
2.5%
97.5%
z val.
p
(Intercept)
0.04
0.04
0.04
-65.98
0.00
edad_jefe
1.01
1.01
1.01
9.98
0.00
Standard errors: MLE
7.3.4 Agregando una variable
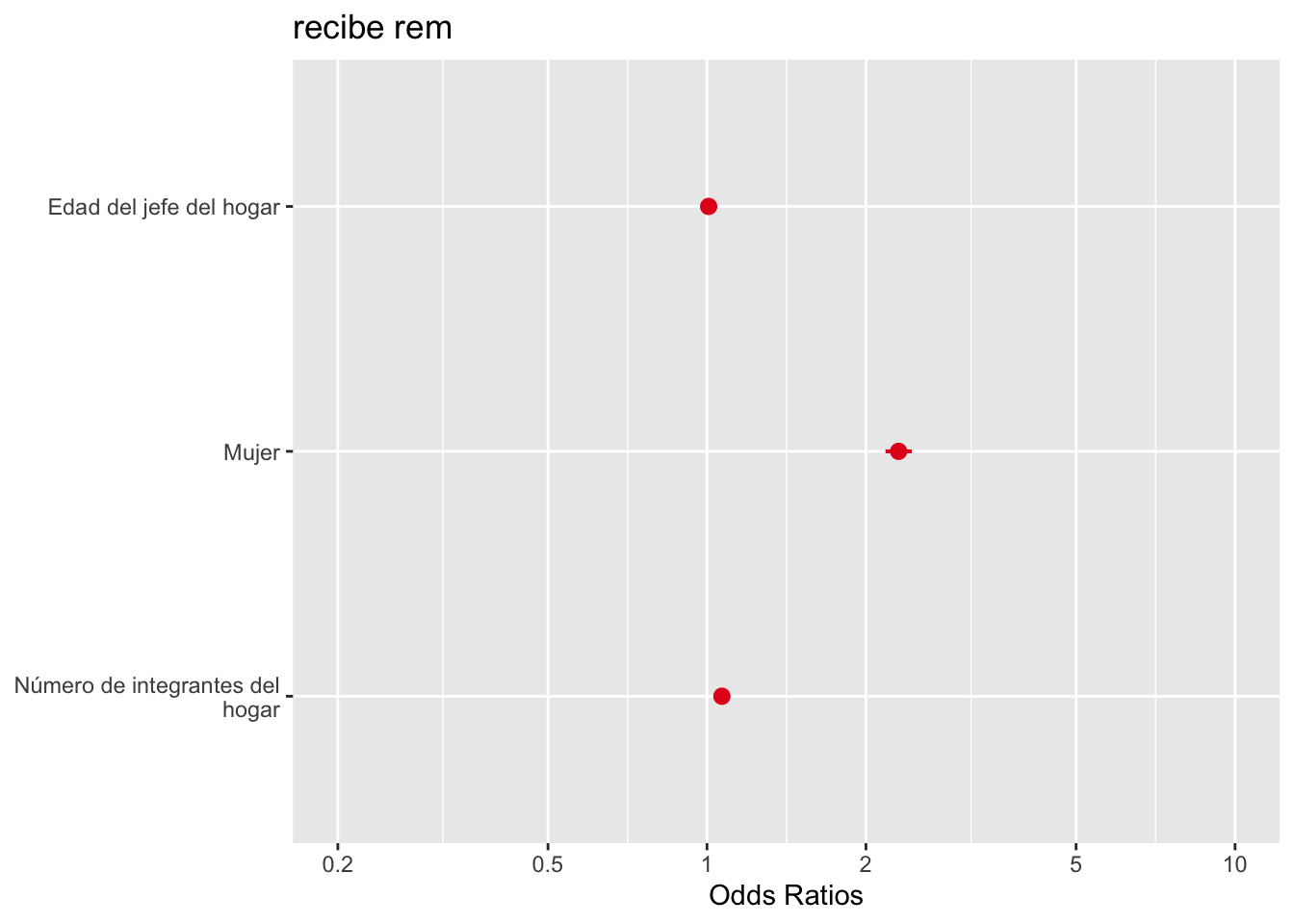
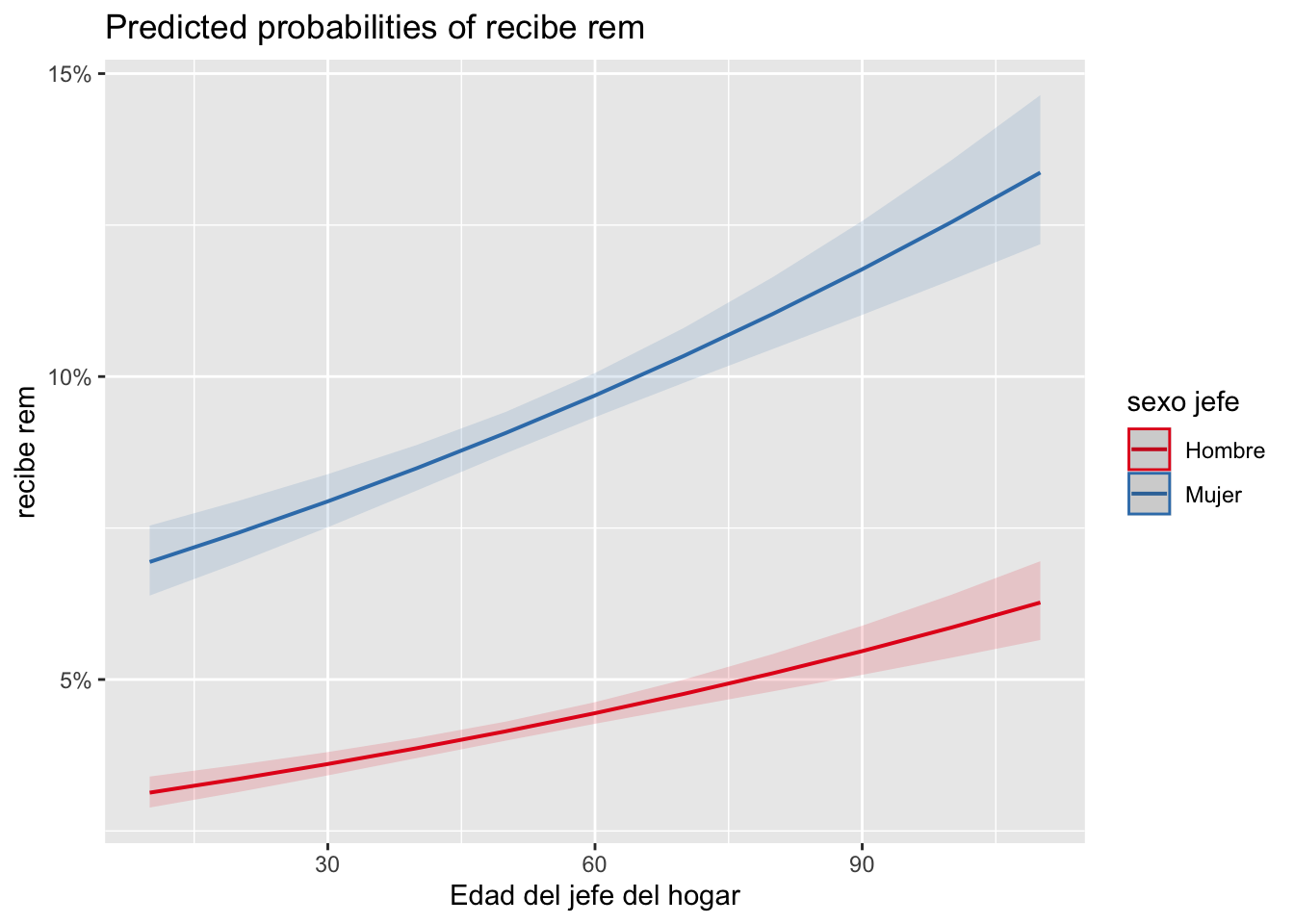
modelo1<-glm(recibe_rem ~ edad_jefe + sexo_jefe, family =binomial("logit"),data=mydata,na.action=na.exclude)summary(modelo1)
Call:
glm(formula = recibe_rem ~ edad_jefe + sexo_jefe, family = binomial("logit"),
data = mydata, na.action = na.exclude)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -3.4304208 0.0499645 -68.657 < 2e-16 ***
edad_jefe 0.0061378 0.0008898 6.898 5.29e-12 ***
sexo_jefeMujer 0.8042078 0.0288932 27.834 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 39801 on 90092 degrees of freedom
Residual deviance: 38945 on 90090 degrees of freedom
AIC: 38951
Number of Fisher Scoring iterations: 6
Este modelo tiene coeficientes que deben leerse “condicionados”. Es decir, en este caso tenemos que el coeficiente asociado a la edad_jefe, mantiene constante el sexo y viceversa.
La devianza es una medida de la bondad de ajuste de los modelos lineales generalizados. O más bien, es una medida de la no-bondad del ajust, puesto que valores más altos indican un peor ajuste.
R nos da medidas de devianza: la devianza nula y la desviación residual. La devianza nula muestra qué tan bien la variable de respuesta se predice mediante un modelo que incluye solo la intersección (gran media).
¿Cómo saber si ha mejorado nuestro modelo? Podemos hacer un test que compare las devianzas(tendría la misma lógica que nuestra prueba F del modelo lineal). Para esto tenemos que instalar un paquete “lmtest”
lrtest0<-lmtest::lrtest(modelo0, modelo1)lrtest0
#Df
LogLik
Df
Chisq
Pr(>Chisq)
2
-1.99e+04
3
-1.95e+04
1
758
8.56e-167
Como puedes ver, el resultado muestra un valor p muy pequeño (<.001). Esto significa que agregar el sexo de la jefatura al modelo lleva a un ajuste significativamente mejor sobre el modelo original.
Podemos seguir añadiendo variables sólo “sumando” en la función
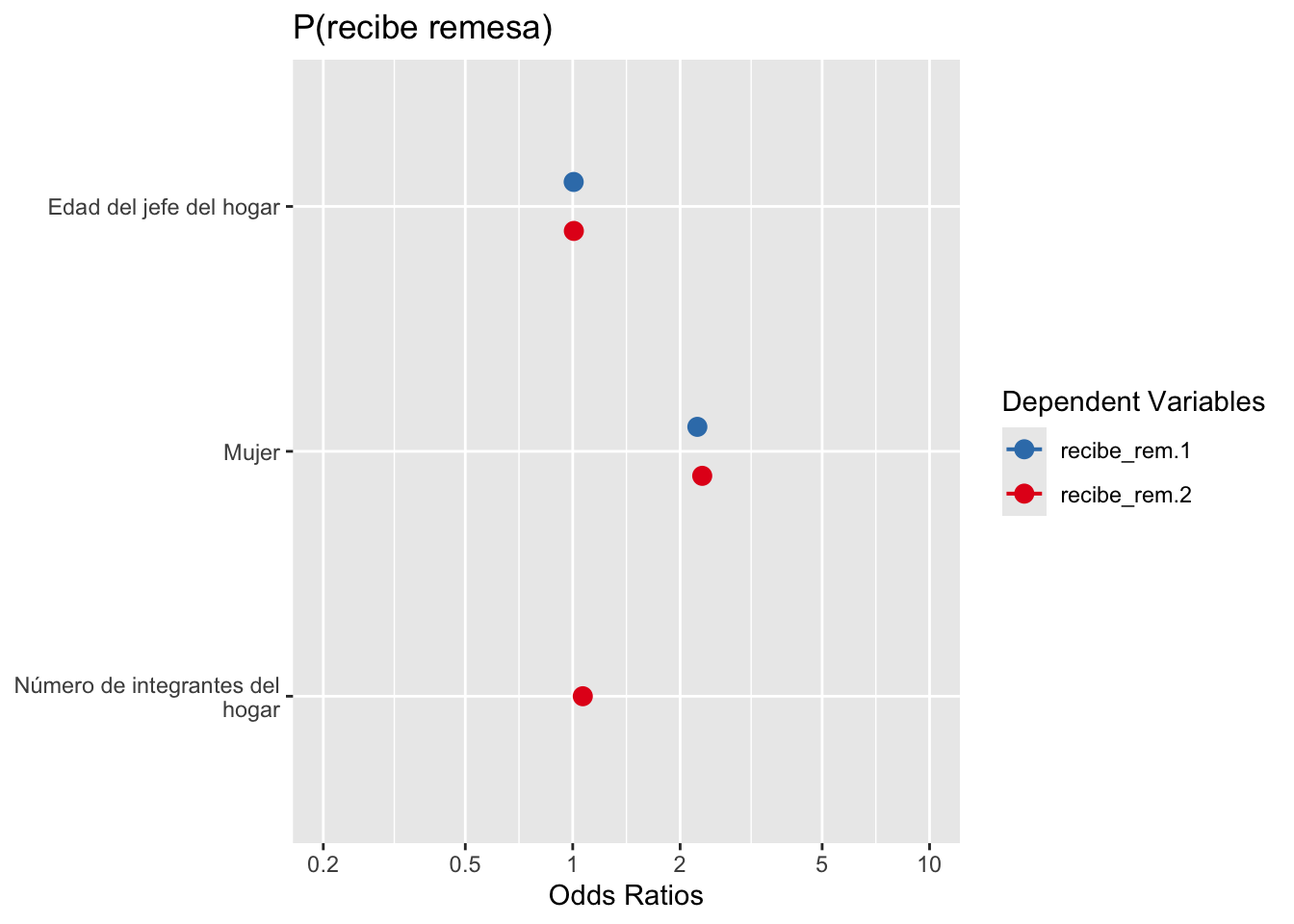
Call:
glm(formula = recibe_rem ~ edad_jefe + sexo_jefe + tot_integ,
family = binomial("logit"), data = mydata, na.action = na.exclude)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -3.7274626 0.0618770 -60.240 < 2e-16 ***
edad_jefe 0.0072699 0.0009066 8.019 1.06e-15 ***
sexo_jefeMujer 0.8356191 0.0291609 28.655 < 2e-16 ***
tot_integ 0.0649789 0.0077567 8.377 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 39801 on 90092 degrees of freedom
Residual deviance: 38877 on 90089 degrees of freedom
AIC: 38885
Number of Fisher Scoring iterations: 6
Y podemos ver si introducir esta variable afectó al ajuste global del modelo
lrtest1<-lrtest(modelo1, modelo2)lrtest1
#Df
LogLik
Df
Chisq
Pr(>Chisq)
3
-1.95e+04
4
-1.94e+04
1
67.6
1.97e-16
7.4.3 Test Hosmer-Lemeshow Goodness of Fit “GOF”
El teste Homer-Lemeshow se calcula sobre los datos una vez que las observaciones se han segmentado en grupos basados en probabilidades predichas similares. Este teste examina si las proporciones observadas de eventos son similares a las probabilidades predichas de ocurrencia en subgrupos del conjunto de datos, y lo hace con una prueba de chi cuadrado de Pearson.
¡Ojo! No queremos rechazar la hipótesis nula. La hipótesis nula sostiene que el modelo se ajusta a los datos por lo tanto no queremos rechazarla.
hoslem.test(mydata$recibe_rem, fitted(modelo2))
Hosmer and Lemeshow goodness of fit (GOF) test
data: mydata$recibe_rem, fitted(modelo2)
X-squared = 382.48, df = 8, p-value < 2.2e-16